平台与数据集
平台与数据集

OctoNav:面向通用具身导航
OctoNav 是一个面向多样导航任务的通用具身导航模型,能够在不同环境中处理复杂导航需求。通过大规模预训练与多模态融合,OctoNav 在复杂室内外场景中展现出稳健表现。
- • 通用导航: 统一模型架构,可处理多类具身导航任务
- • 多模态融合: 融合视觉感知与语言指令,实现稳健控制
- • 跨环境泛化: 在多样和未见场景中展现较强泛化能力
Ziqin Wang, Xiangyu Wang, Jinyu Chen, Ruipu Wu, Linjiang Huang, Yue Liao, Si Liu

面向真实无人机视觉语言导航:平台、基准与方法
该平台面向无人机视觉语言导航,弥合仿真与真实部署之间的差距,并提供真实场景与标准化评测指标,推动自主无人机系统研究。
- • 平台: 面向无人机导航的仿真与真实测试环境
- • 基准: 包含真实场景与标准化评测指标
- • 方法: 面向视觉语言导航的 sim-to-real 方法
Xiangyu Wang, Donglin Yang, Ziqin Wang, Hohin Kwan, Jinyu Chen, Wenjun Wu, Hongsheng Li, Yue Liao, Si Liu
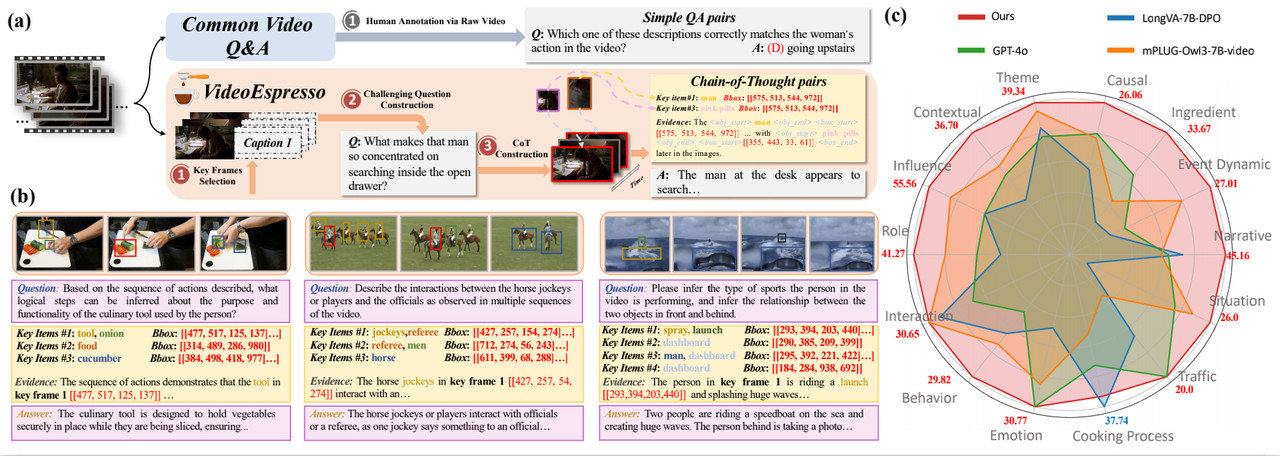
VideoEspresso:基于核心帧选择的大规模细粒度视频推理链式思维数据集
VideoEspresso 是面向细粒度视频推理的大规模数据集,通过链式思维标注与核心帧选择方法增强视频理解和推理能力。
- • 数据规模: 覆盖多样视频场景与推理任务的大规模数据
- • 链式思维: 面向细粒度视频理解的结构化推理过程
- • 核心帧选择: 识别并利用关键帧以提升推理效率
Songhao Han, Wei Huang, Hairong Shi, Le Zhuo, Xiu Su, Shifeng Zhang, Xu Zhou, Xiaojuan Qi, Yue Liao, Si Liu
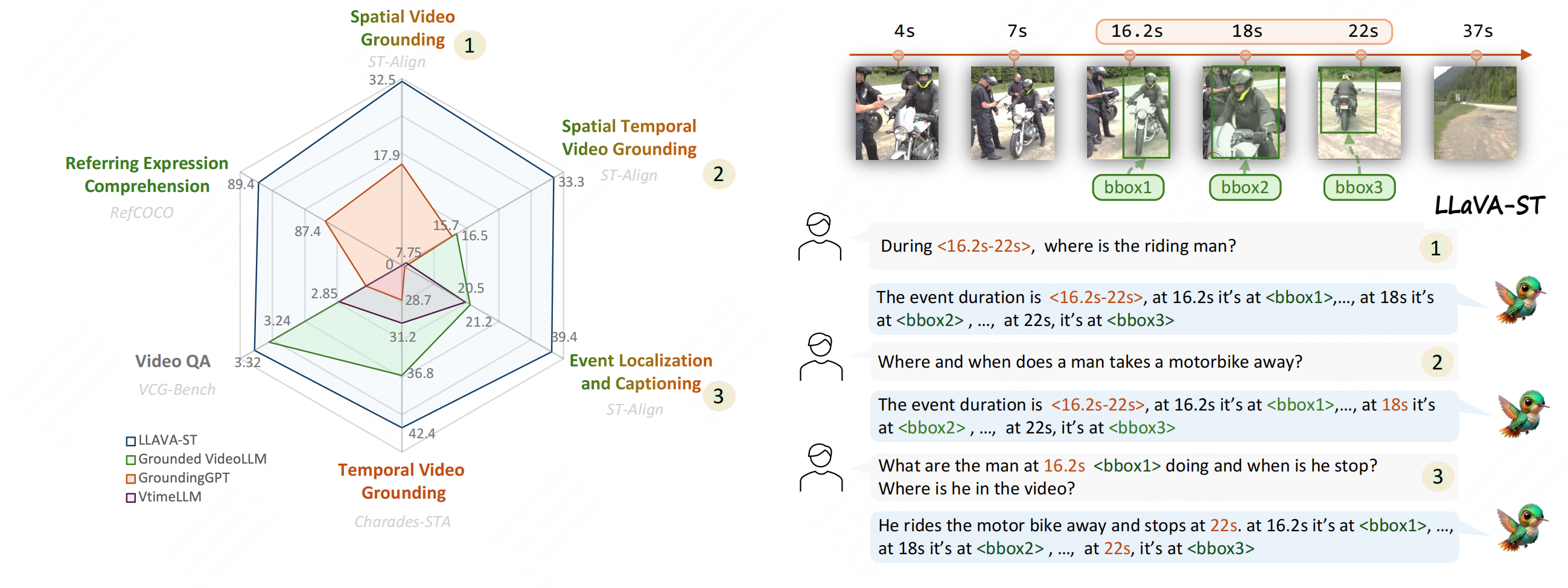
LLaVA-ST:面向细粒度时空理解的多模态大语言模型
LLaVA-ST 是专为细粒度时空理解设计的多模态大语言模型,能够精确理解视觉内容中的复杂空间与时间关系。
- • 多模态架构: 融合视觉与语言以进行时空推理
- • 细粒度理解: 精确理解复杂空间和时间关系
- • 应用: 提升视频理解与视觉问答等任务表现
Hongyu Li, Jinyu Chen, Ziyu Wei, Shaofei Huang, Tianrui Hui, Jialin Gao, Xiaoming Wei, Si Liu

Video2BEV:将无人机视频转换为 BEV 表示用于视频地理定位
该方法将无人机视频转换为鸟瞰视角表示,以提升视频地理定位能力,并从空中视频中实现更准确的空间理解与定位。
- • BEV 转换: 将无人机视频转换为鸟瞰视角表示
- • 地理定位: 基于空中视频进行准确空间理解与定位
- • 视频方法: 利用时序信息提升定位鲁棒性
Hao Ju, Shaofei Huang, Si Liu, Zhedong Zheng
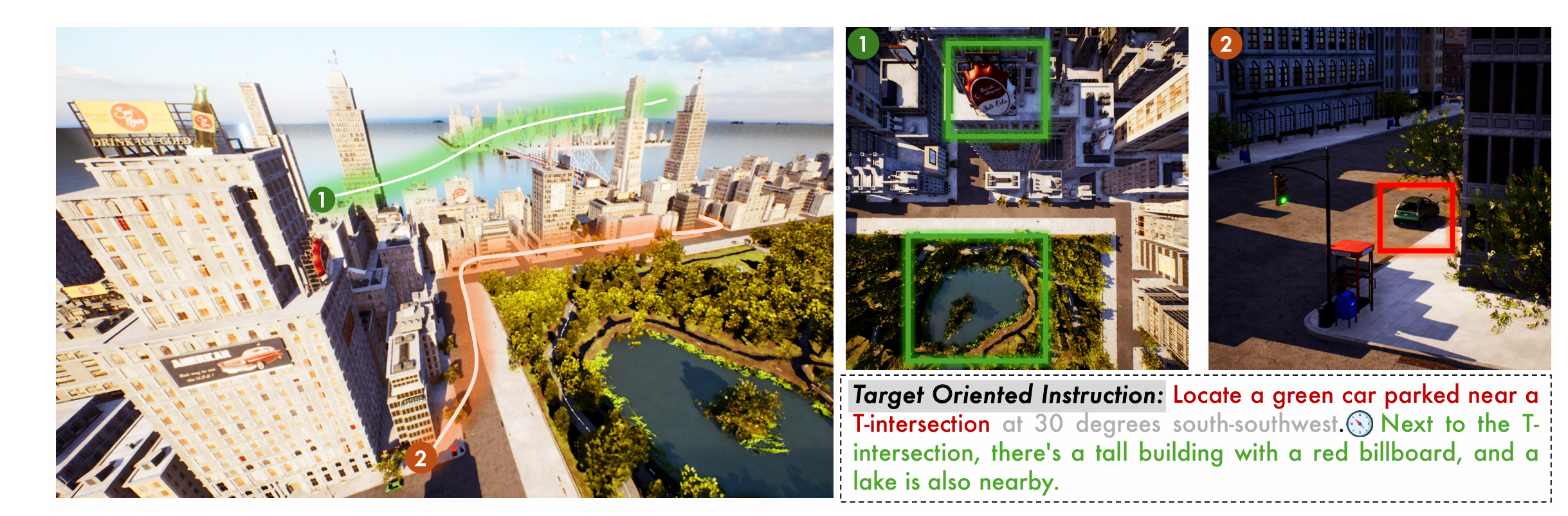
AeroDuo:面向无人机视觉语言导航的空中双智能体系统
AeroDuo 面向无人机视觉语言导航,结合视觉感知与自然语言理解,实现更直观的无人机控制与导航。
- • 双系统设计: 结合视觉处理与语言理解的创新架构
- • 视觉语言融合: 实现视觉感知与自然语言理解的协同
- • 直观控制: 通过自然语言指令进行用户友好的无人机导航
Ruipu Wu, Yige Zhang, Jinyu Chen, Linjiang Huang, Shifeng Zhang, Xu Zhou, Liang Wang, Si Liu
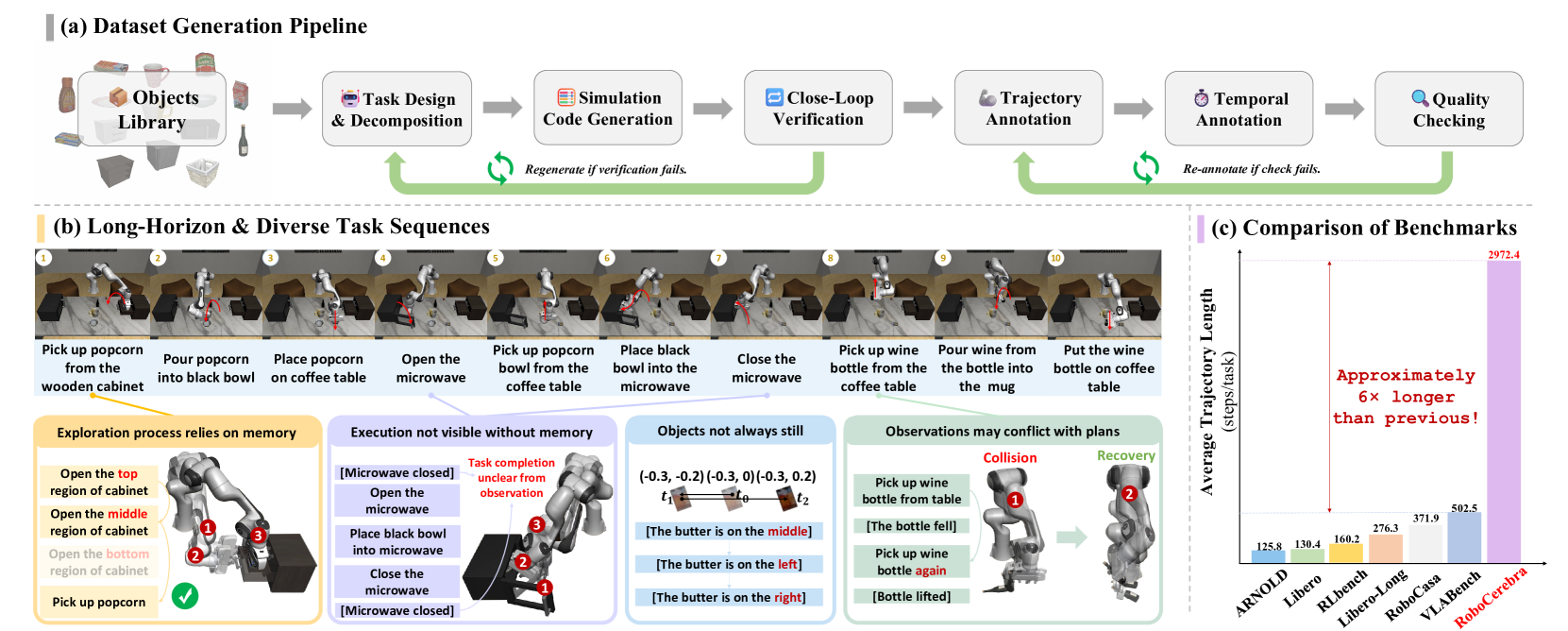
RoboCerebra:长程机器人操作评测的大规模基准
RoboCerebra 是面向长程机器人操作任务的综合评测基准,提供标准化评测协议和多样场景,推动具身智能与机器人研究。
- • 大规模基准: 面向长程机器人操作的综合评测框架
- • 标准协议: 覆盖多样场景的一致评测指标与方法
- • 研究推动: 通过系统评测推动具身智能与机器人研究
Songhao Han, Boxiang Qiu, Yue Liao, Siyuan Huang, Chen Gao, Shuicheng Yan, Si Liu
Hi AirStar:带我去羽毛球场
AirStar 是一个可通过自然语言命令引导用户到达指定地点的交互式演示系统,展示视觉语言导航在真实场景中的应用。
- • 交互系统: 通过自然语言交互实现实时导航
- • 实际应用: 展示视觉语言导航在真实场景中的能力
- • 用户体验: 通过对话式交互实现直观位置引导
Ziqin Wang, Jinyu Chen, Xiangyi Zheng, Qinan Liao, Linjiang Huang, Si Liu