平台与数据集
Platforms & Datasets

Towards Realistic UAV Vision-Language Navigation: Platform, Benchmark, and Methodology
We present a comprehensive platform for UAV vision-language navigation that bridges the gap between simulation and real-world deployment. Our benchmark provides realistic scenarios and evaluation metrics for advancing autonomous UAV systems.
- • Platform: Comprehensive simulation and real-world testing environment for UAV navigation
- • Benchmark: Realistic scenarios with standardized evaluation metrics
- • Methodology: Novel approach bridging sim-to-real gap in vision-language navigation
Xiangyu Wang, Donglin Yang, Ziqin Wang, Hohin Kwan, Jinyu Chen, Wenjun Wu, Hongsheng Li, Yue Liao, Si Liu
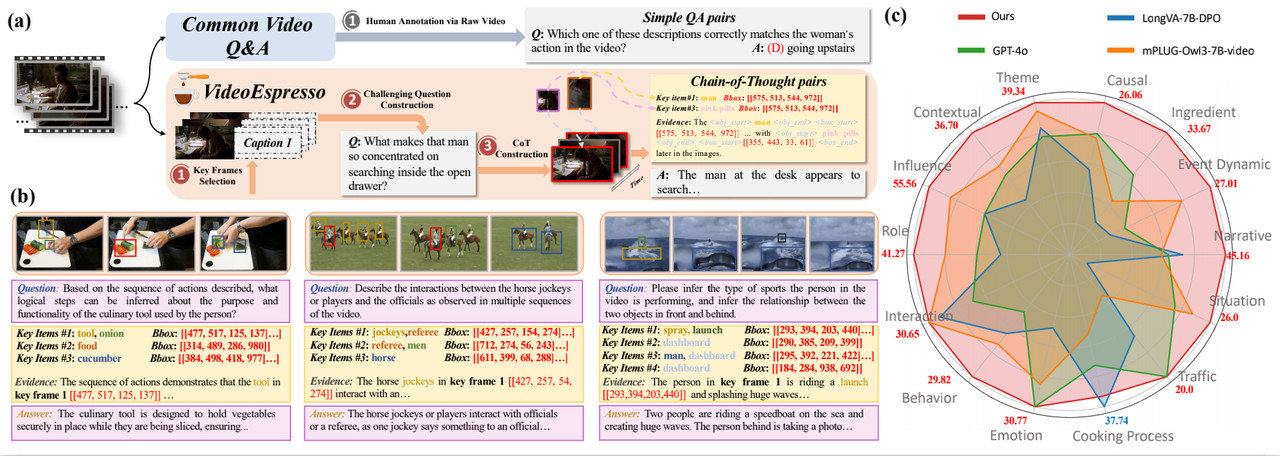
VideoEspresso: A Large-Scale Chain-of-Thought Dataset for Fine-Grained Video Reasoning via Core Frame Selection
A large-scale dataset designed for fine-grained video reasoning through chain-of-thought methodology. We introduce core frame selection techniques to enhance video understanding and reasoning capabilities.
- • Dataset Scale: Large-scale collection with diverse video scenarios and reasoning tasks
- • Chain-of-Thought: Structured reasoning methodology for fine-grained video understanding
- • Core Frame Selection: Novel technique to identify and leverage key frames for efficient reasoning
Songhao Han, Wei Huang, Hairong Shi, Le Zhuo, Xiu Su, Shifeng Zhang, Xu Zhou, Xiaojuan Qi, Yue Liao, Si Liu
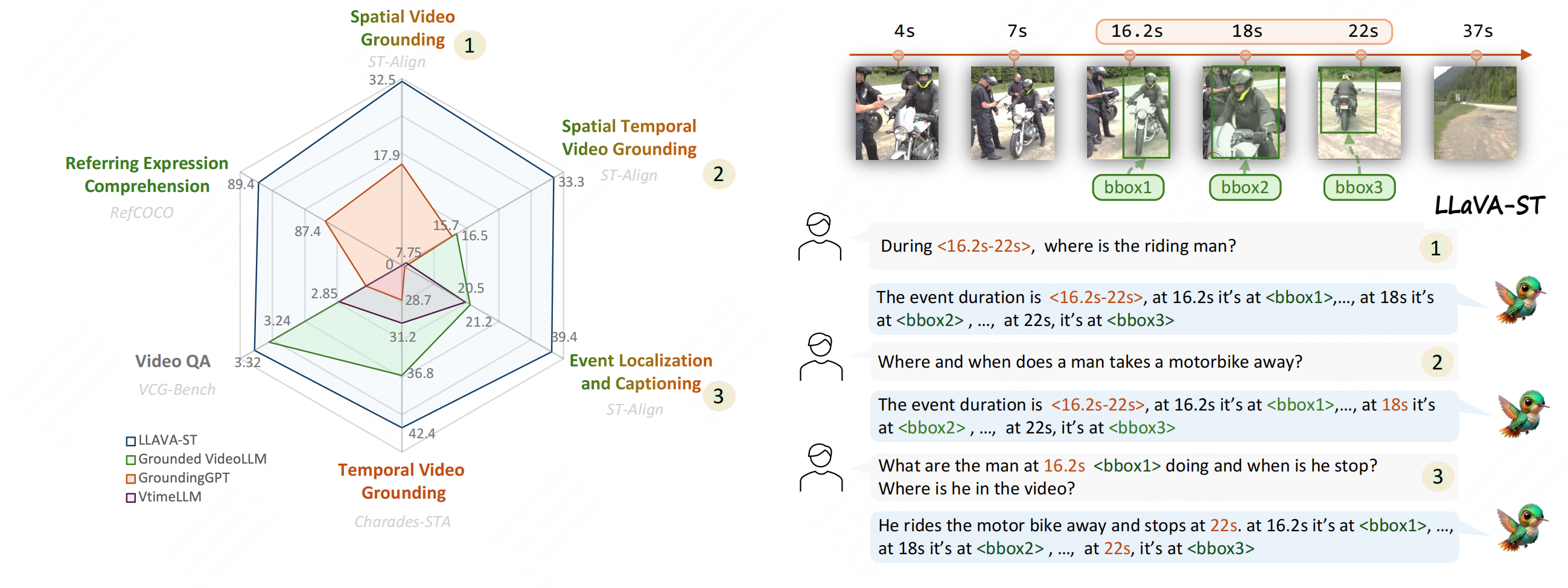
LLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding
A multimodal large language model specifically designed for fine-grained spatial-temporal understanding. LLaVA-ST enables precise comprehension of complex spatial and temporal relationships in visual content.
- • Multimodal Architecture: Advanced integration of vision and language for spatial-temporal reasoning
- • Fine-Grained Understanding: Precise comprehension of complex spatial and temporal relationships
- • Applications: Enhanced performance in video understanding and visual question answering
Hongyu Li, Jinyu Chen, Ziyu Wei, Shaofei Huang, Tianrui Hui, Jialin Gao, Xiaoming Wei, Si Liu

Video2BEV: Transforming Drone Videos to BEVs for Video-based Geo-localization
We transform drone videos into bird's-eye-view representations for improved geo-localization. This approach enables accurate spatial understanding and localization from aerial video footage.
- • BEV Transformation: Novel method to convert drone videos into bird's-eye-view representations
- • Geo-localization: Accurate spatial understanding and localization from aerial footage
- • Video-based Approach: Leverages temporal information for robust localization performance
Hao Ju, Shaofei Huang, Si Liu, Zhedong Zheng
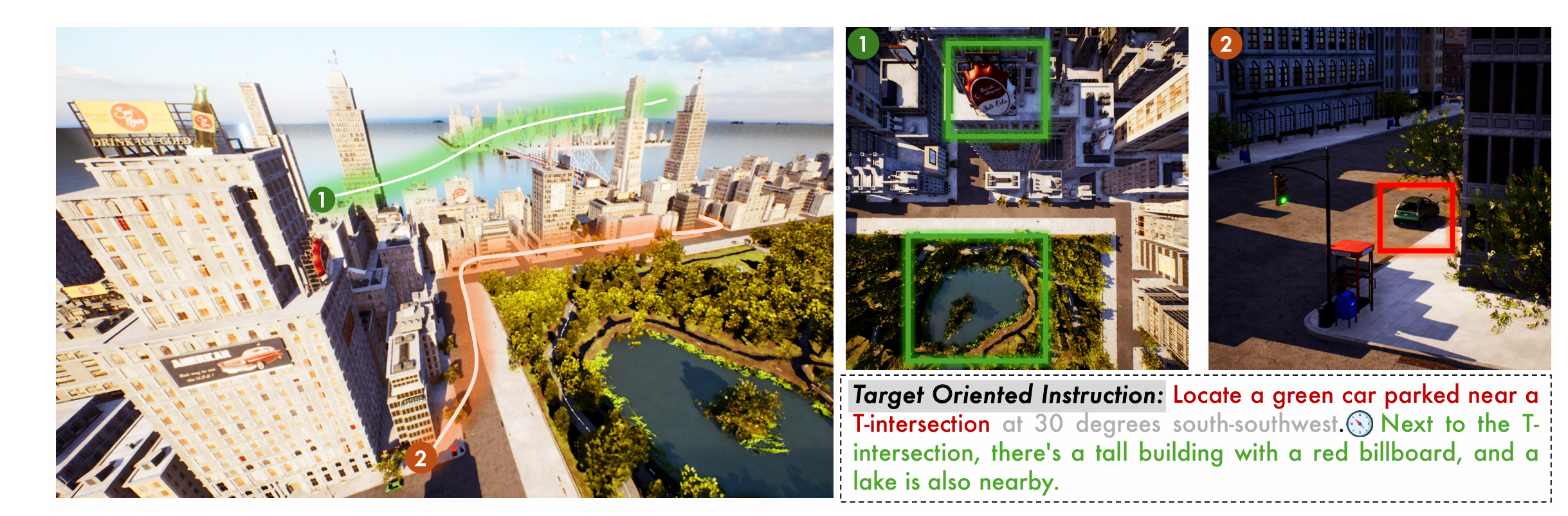
AeroDuo: Aerial Duo for UAV-based Vision and Language Navigation
An innovative dual-system approach for UAV-based vision and language navigation. AeroDuo combines visual perception with natural language understanding to enable intuitive UAV control and navigation.
- • Dual-System Design: Innovative architecture combining visual and linguistic processing
- • Vision-Language Integration: Seamless fusion of visual perception and natural language understanding
- • Intuitive Control: Natural language commands for user-friendly UAV navigation
Ruipu Wu, Yige Zhang, Jinyu Chen, Linjiang Huang, Shifeng Zhang, Xu Zhou, Liang Wang, Si Liu
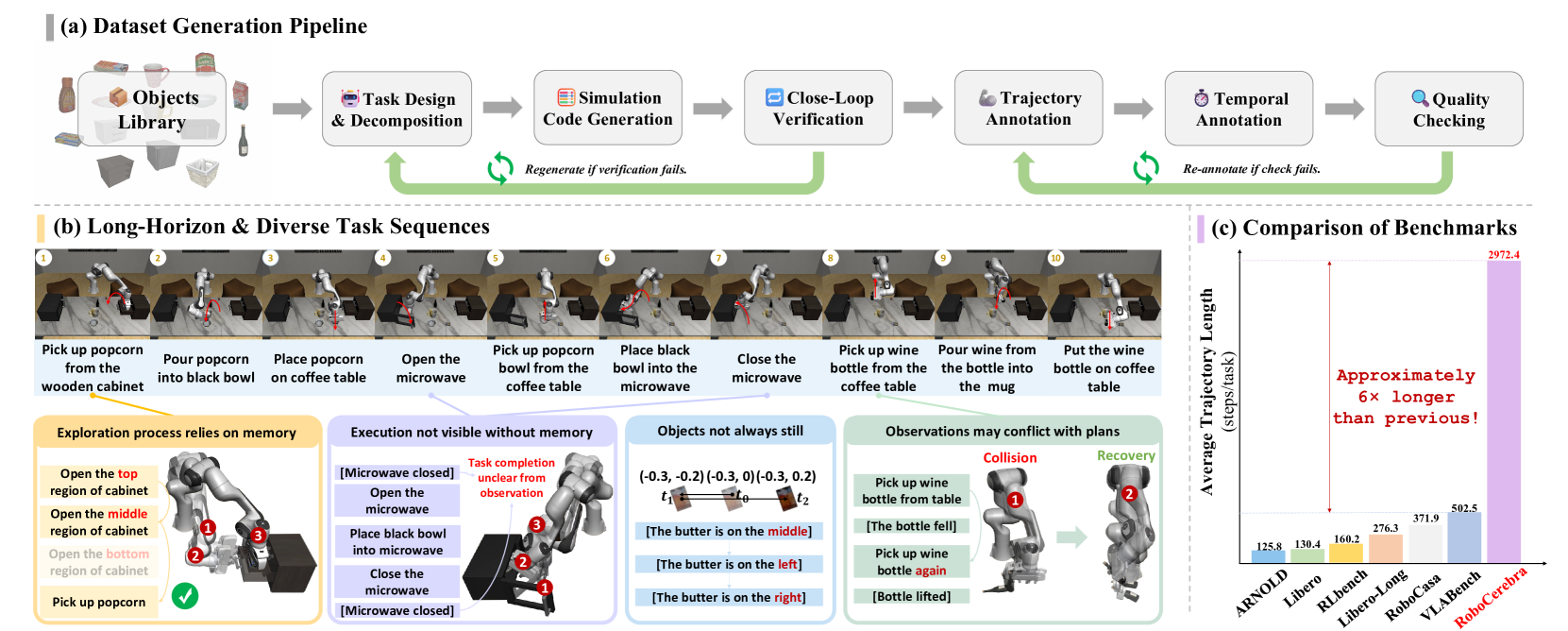
RoboCerebra: A Large-scale Benchmark for Long-horizon Robotic Manipulation Evaluation
A comprehensive benchmark for evaluating long-horizon robotic manipulation tasks. RoboCerebra provides standardized evaluation protocols and diverse scenarios to advance research in embodied AI and robotics.
- • Large-scale Benchmark: Comprehensive evaluation framework for long-horizon robotic manipulation
- • Standardized Protocols: Consistent evaluation metrics and methodologies across diverse scenarios
- • Research Advancement: Advances embodied AI and robotics research through systematic evaluation
Songhao Han, Boxiang Qiu, Yue Liao, Siyuan Huang, Chen Gao, Shuicheng Yan, Si Liu
Hi AirStar: Guide Me to the Badminton Court
An interactive demonstration system that guides users to specific locations using natural language commands. This demo showcases practical applications of vision-language navigation in real-world scenarios.
- • Interactive System: Real-time guidance through natural language interaction
- • Practical Application: Demonstrates vision-language navigation in real-world settings
- • User Experience: Intuitive location guidance with conversational interface
Ziqin Wang, Jinyu Chen, Xiangyi Zheng, Qinan Liao, Linjiang Huang, Si Liu